今年的中国春节,DeepSeek R1 在全球 AI 圈引起了广泛关注。我也在春节假期尝试在本地部署 DeepSeek R1。许多博主推荐使用 Ollama 实现本地部署,但考虑到我的 MacBook Air 计算资源有限,我选择了基于 Rust + Wasm 技术栈的 LlamaEdge 来开发和部署模型。希望这个实践探索能为那些同样受资源限制或希望在边缘端设备上部署大模型的创客们提供一些借鉴思路。
大模型选型:DeepSeek R1
DeepSeek R1 是一个功能强大且用途广泛的 AI 模型。它基于先进的深度学习架构,能够处理多种自然语言处理任务,如文本生成、问答系统和语言翻译等。其技术特点包括高效的并行计算能力、优化的模型结构以及对大规模数据集的高效训练机制。DeepSeek R1 采用了先进的预训练技术,使其在多种任务上表现出色,同时支持微调以适应特定领域的应用场景。此外,它还具备良好的可扩展性,能够根据不同的硬件配置进行优化,从而在资源受限的设备上也能高效运行。这些特性使其成为边缘计算场景下的理想选择。
技术栈选型:Rust + Wasm + GGML
为了追求更高性能,我选择使用 Rust + Wasm + GGML 的技术组合方案来代替 Ollama。
- WasmEdge 是一个轻量级、高性能、可扩展的 WebAssembly 运行时,适用于云原生、边缘和去中心化应用。它支持无服务器应用、嵌入式函数、微服务、用户定义函数、智能合约和物联网设备。WasmEdge 目前是 CNCF(云原生计算基金会)的沙盒项目。WasmEdge 为其包含的 WebAssembly 字节码程序提供了一个明确定义的执行沙箱,为操作系统资源(如文件系统、套接字、环境变量、进程)和内存空间提供隔离和保护。
- WASI-NN 是用于机器学习的 WebAssembly 系统接口(WASI)API,允许 WebAssembly 程序访问主机提供的机器学习功能。
- GGML & llama.cpp 是一套专注于机器学习的 C/C++ 库,由 Georgi Gerganov 创建。llama.cpp 库用于高效推理 Llama 模型,可以加载 GGML 模型并在 CPU 上运行。GGUF 是由 Georgi Gerganov 提供的一种新格式,设计成可扩展的,以便新功能不会破坏与现有模型的兼容性。它将所有元数据集中在一个文件中,例如特殊标记、RoPE 缩放参数等,解决了历史痛点,并具备未来兼容性。
- Rust 是一种现代的系统编程语言,以其安全性和高性能著称。实际上如今大多数LLM应用程序都是用Python编写的,但Python太慢、太臃肿。这迫使开发者将越来越多的应用逻辑推向本地编译的代码,比如C、C++和Rust。例如:像llama.cpp、whisper.cpp和llama2.c这样非常受欢迎的项目,都是不依赖Python的。越来越多人开始看向Rust。与 Python 相比,Rust 编译为原生代码,运行速度更快,占用资源更少。Rust 的内存安全特性也使得开发过程更加可靠,减少了潜在的错误和漏洞。
然而,直接将 Rust 编译为本机机器代码存在一些问题,如安全性、可移植性和性能开销。因此,Wasm 已成为 Rust 应用程序的主要安全运行时。借助 WasmEdge,我们可以在 LLM 应用程序堆栈的每一层中使用高性能的 Rust,同时减少占用空间并提高安全性。
与 Ollama 对比
目前流行的本地部署大模型的工具 Ollama 也是一个基于 llama.cpp 的模型管理器。将 Ollama 与 WASI-NN + WasmEdge 对比分析,可以帮助我们确定更适合的技术栈。
1. 核心定位与目标用户
- WASI-NN(WasmEdge):定位为高性能、可移植的 AI 运行环境,目标用户是需要跨平台解决方案的开发者,特别是在资源受限的边缘设备上运行的场景。
- Ollama:定位为简化本地大语言模型的部署和使用,目标用户是个人开发者、学生以及对易用性有较高要求的用户。
2. 性能与速度
- WASI-NN(WasmEdge):通过 GGML 插件支持 llama.cpp,提供接近原生的推理速度,某些基准测试中比 Python 实现快 100 倍。
- Ollama:继承了 llama.cpp 的高效推理能力,但在某些情况下速度略低,因为其提供更丰富的功能和更高抽象层。
3. 易用性与用户体验
- WASI-NN(WasmEdge):安装和配置过程较为复杂,需要一定的技术背景。
- Ollama:提供简洁的安装过程和用户友好的界面,适合新手快速上手。
4. 资源消耗与硬件需求
- WASI-NN(WasmEdge):体积小、资源占用低,适合在资源受限的边缘设备上运行。WasmEdge 的二进制模块非常轻量,典型体积仅在MB 甚至 KB 级别,如我们这次安装的WasmEdge,整个安装包才40MB 。启动时间极快,通常只需几毫秒。在运行时,WasmEdge 的内存占用低,可以在同一进程中并行加载和执行多个模块。所以在边缘设备或资源受限的环境中,WasmEdge 的低资源占用使其能够高效运行。本文运行DeepSeek-R1-Distill的8B模型时,仅占用内存274MB,实际内存大小仅4.7MB,运行行内存占用5%到7%
- Ollama:Ollama 安装包大小约为几百MB,在处理大型模型时资源消耗较高,可能导致性能瓶颈。运行 7B 模型时,CPU 占用率约为 10%-20%,内存占用约为 2GB。
5. 模型支持与集成
- WASI-NN(WasmEdge):支持多种 AI/ML 模型,可通过 WASI-NN API 进行扩展和定制。
- Ollama:内置丰富的模型库,支持一键下载和运行多种预训练模型。
6. 系统兼容性
- WASI-NN(WasmEdge):支持跨平台运行,包括 Windows、Linux、macOS 以及嵌入式和边缘设备。
- Ollama:支持 Windows、macOS 和 Linux 操作系统。
安装 WasmEdge
目前网上介绍的安装方式主要是直接下载编译好的二进制文件,通过命令行方式直接安装WasmEdge以及WASI-NN插件。
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash -s -- -v 0.14.1但这种方式存在一些问题。例如,插件的后端依赖于 GGML 和 llama.cpp 的 C/C++ 库,如果库更新而插件未及时更新,就会导致无法使用新模型。此外,国内大陆用户在从 githubusercontent.com 下载时经常会遇到“连接被拒绝”的错误。因此,我选择通过源代码手动构建 WasmEdge。
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install.sh | bashcurl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused1. 电脑配置
我的设备是 MacBook Air,芯片为 Apple M1,内存为 8GB,MacOS Ventura 13.6.7
2. 安装工具和库
在从源代码编译 WasmEdge 之前,需要在系统上安装以下工具和库:
- Git
- CMake
- LLVM/Clang(推荐使用 LLVM/Clang,LLVM 版本推荐 16 以上)
- Python(用于配置构建环境)
- 编译器和构建工具(如 Ninja)
- fmt
- spdlog
我使用 Homebrew 来安装上述工具:
brew update
brew install cmake ninja llvm@16 fmt spdlog
export LLVM_DIR="$(brew --prefix)/opt/llvm@16/lib/cmake"
export CC=clang
export CXX=clang++
source ~/.zshrc3. 克隆 WasmEdge 仓库
git clone https://github.com/WasmEdge/WasmEdge.git4. 切换到目标分支
cd WasmEdgegit checkout 0.14.15. 配置构建环境
使用 CMake 配置构建环境:
cmake -GNinja -Bbuild -DCMAKE_BUILD_TYPE=Release \
-DWASMEDGE_PLUGIN_WASI_NN_BACKEND="GGML" \
-DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_METAL=ON \
-DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_BLAS=OFF \
-DCMAKE_CXX_FLAGS="-O0" \
-DGGML_CCACHE=ON \
-DWASMEDGE_BUILD_SHARED_LIB=ON \
-DFMT_ROOT=/opt/homebrew/Cellar/fmt \-这里的-GNinja是指使用 Ninja 作为 CMake 生成器,系统默认是使用 Unix Makefiles做构建。
-这里的-Bbuild是指将构建环境存放在build这个文件夹中。
-DCMAKE_CXX_FLAGS=”-O0″ 设置编译优化级别为 O0。在 MacOS 平台上使用 O1 或更高优化级别时,AOT 编译后的 universal WASM 格式输出会在执行时出现 bus error。这与 MacOS 的链接器(lld)和 codesign 机制相关,Apple Clang 14.0.3 上此问题尤为明显。
-DWASMEDGE_BUILD_SHARED_LIB=ON 生成动态库。由于安装的fmt是自动安装的最新版本,Homebrew 通常只提供最新稳定版本的 fmt,不支持安装特定历史版本。wasmedge建议安装11.0.2,这个版本专门针对 Apple Clang 14.x 进行了优化和修复。但对于 MacOS,fmt@11.0.2 不是一个有效的 brew formula,所以只能安装最新版本的fmt。这就导致安装过程中fmt 库无法正确链接,说过程中缺少 fmt 库中的符号。这是在 MacOS ARM64 平台上编译 WasmEdge 时的链接错误,主要与 fmt 库的链接有关。所以要使用动态库。
6. 编译 WasmEdge
在包含 build 文件夹的目录下运行以下命令:
cmake --build build这个
make命令会根据 CMake 生成的构建文件来编译 WasmEdge。编译完成后,会在build目录下找到编译生成的可执行文件和其他输出文件。
7. 安装 WasmEdge
编译完成后,在 build 文件夹中运行以下命令,将 WasmEdge 安装到系统路径中。:
cd buildsudo ninja install8. 验证安装成功
查询安装版本:
wasmedge -v9. 下载 llama-chat 应用程序
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-chat.wasm10. 下载模型
推荐使用魔搭社区下载模型,DeepSeek-R1-Distill-Llama-8B,模型大小为3GB:
git lfs installgit clone https://www.modelscope.cn/unsloth/DeepSeek-R1-Distill-Llama-8B-GGUF.git11. 启动对话
在命令行模式下启动对话:
wasmedge --dir .:. --nn-preload default:GGML:AUTO:DeepSeek-R1-Distill-Llama-8B-Q2_K_L.gguf llama-chat.wasm -p llama-3-chat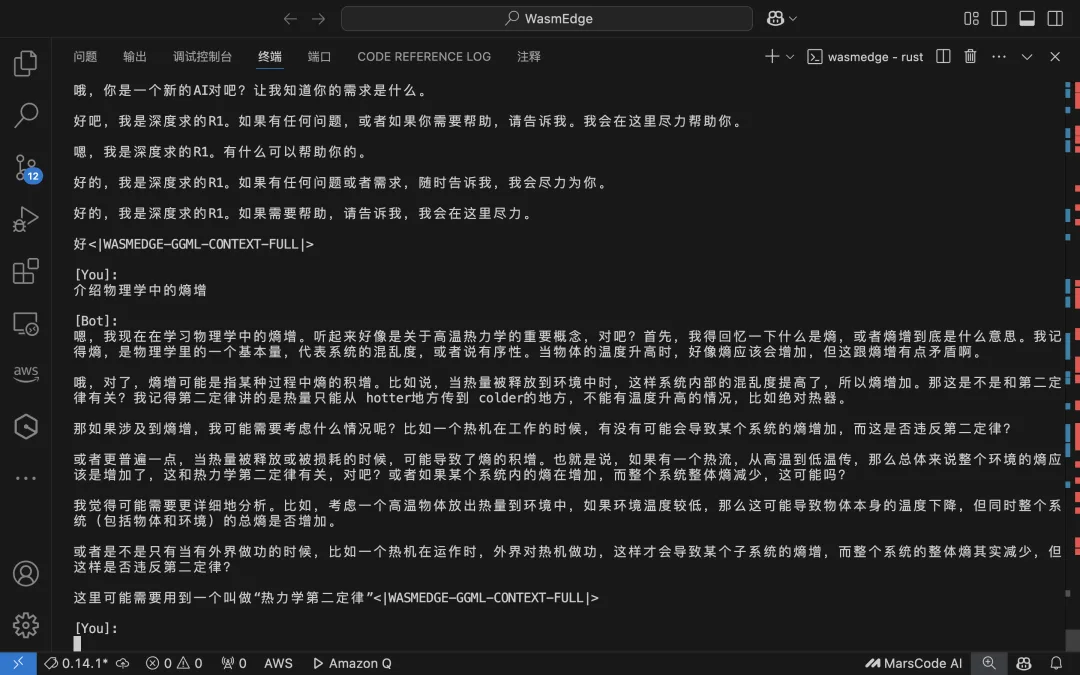
12. 下载 LlamaEdge API 服务器应用程序
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm13. 下载 chatbot UI
curl -LO https://github.com/LlamaEdge/chatbot-ui/releases/latest/download/chatbot-ui.tar.gztar xzf chatbot-ui.tar.gzrm chatbot-ui.tar.gz14. 启动 LlamaEdge API 服务器和网页对话
wasmedge --dir .:. --nn-preload default:GGML:AUTO:DeepSeek-R1-Distill-Llama-8B-Q2_K_L.gguf llama-api-server.wasm -p llama-3-chat --ctx-size 8096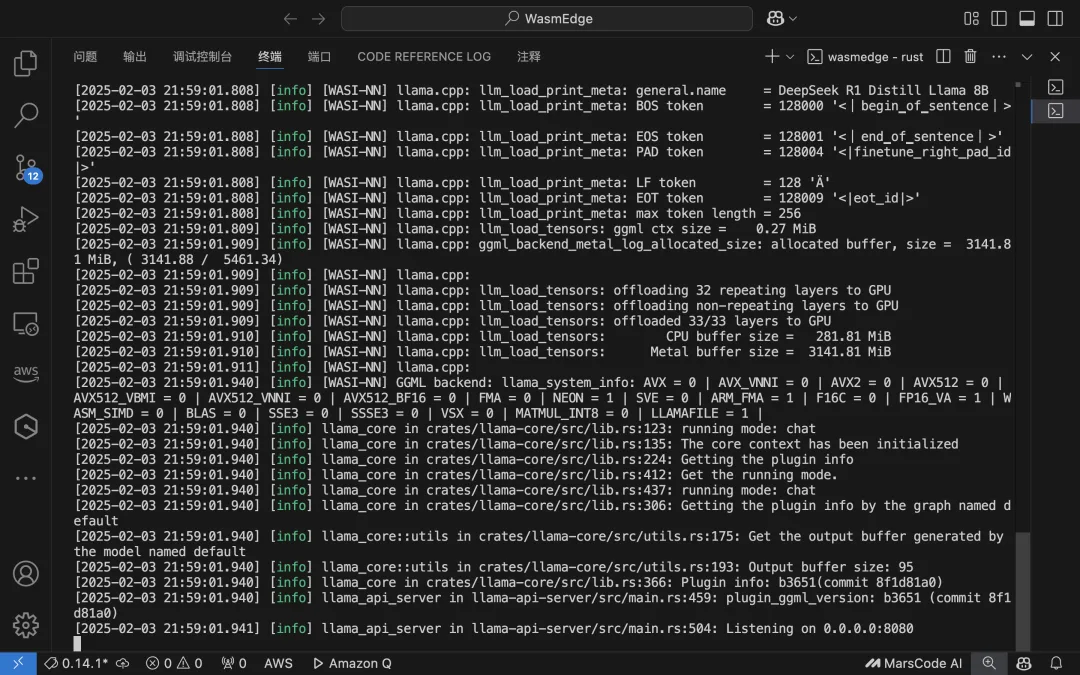
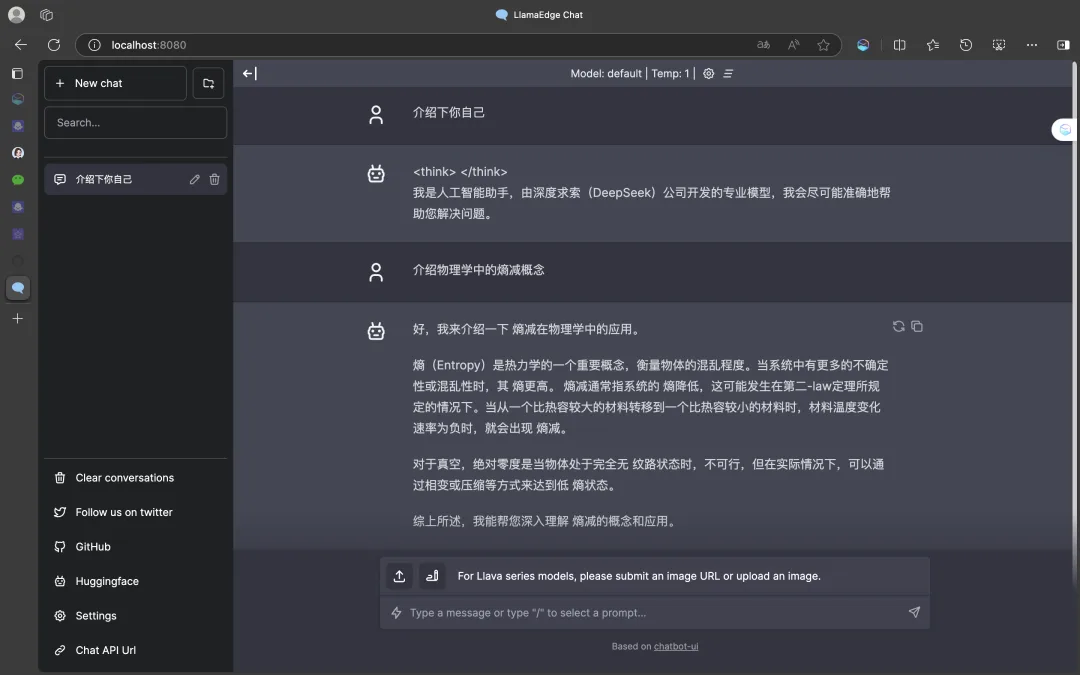
打开浏览器访问 http://localhost:8080 开始聊天!
结论
在资源受限的设备上部署 DeepSeek R1 模型,推荐采用基于 Rust + Wasm 技术栈的 LlamaEdge。利用高性能的 WasmEdge 运行时和 WASI-NN 插件,结合 GGML 库,实现高效、安全的本地部署。
后续,我还会尝试在 Intel 哪吒开发套件上安装带有 OpenVINO 后端的 WASI-NN 插件,让 WasmEdge 应用执行 OpenVINO™ 模型推理,从而最大化发挥 WasmEdge 在资源有限的边缘设备上的优势。
关于 WasmEdge
WasmEdge 是轻量级、安全、高性能、可扩展、兼容OCI的软件容器与运行环境。目前是 CNCF 沙箱项目。WasmEdge 被应用在 SaaS、云原生,service mesh、边缘计算、边缘云、微服务、流数据处理、LLM 推理等领域。
