💥 “实验室算力荒漠有救了!开源框架X-R1逆袭:4块显卡1小时训出7B模型,成本够买5杯奶茶!”
当大厂用千卡集群烧钱时,我们找到了破局的关键——
- 👉 博士生为跑实验深夜偷用服务器被导师抓包
- 👉 创业公司看着天价云账单放弃模型微调
- 👉 技术博客教程永远以“假设你有A100集群”开头…
今天要介绍的 X-R1框架 正在用强化学习重构训练规则!这个由华人团队研发的开源工具,首次让3090显卡集群高效训练7B规模的模型,1小时训练成本仅需9.9美元。已有先行者使用X-R1完成:
- ✅ 32B模型在64G显存环境中的分布式训练
- ✅ 企业级对话模型微调成本降低87%
- ✅ 单卡实现R1-Zero算法的在线采样优化
是时候打破算力垄断了——你的显卡准备好了吗?
X-R1 是什么

X-R1 是一个基于强化学习的低成本训练框架,专为加速大规模语言模型的后训练(Scaling Post-Training)而设计。它能够在极低的成本下,使用常见的硬件配置(如4块3090或4090 GPU),在1小时内完成0.5B规模的R1-Zero模型训练,成本低于10美元。
此外,X-R1支持更大规模的模型(如1.5B、7B、32B等),并提供多种不同规模的数据集以实现快速训练循环。
X-R1的主要功能
- 低成本训练:仅需4块3090/4090 GPU,1小时内完成训练,成本低于10美元。
- 模型规模支持:支持0.5B、1.5B、7B、32B等多种规模的模型。
- 数据集:提供0.75k、1.5k、7.5k等不同规模的数据集,适用于快速训练循环。
- 日志记录:记录GRPO在线采样数据到日志文件。
- 扩展性与灵活性:提供详细的配置文件和训练脚本,方便用户根据需求进行定制。
X-R1的技术原理
- 强化学习(Reinforcement Learning, RL):X-R1通过强化学习优化训练过程,基于奖励函数,模型根据奖励信号调整参数,最大化累积奖励。采用GRPO(Gradient-based Reinforcement Policy Optimization)技术进行在线采样,从而提升训练效率与模型性能。
- 分布式训练:X-R1支持分布式训练,利用多GPU并行计算加速训练过程。基于配置文件(如Zero3.yaml),用户可以灵活设置训练环境,实现高效的并行训练。通过采用DeepSpeed等分布式训练框架,优化内存使用和计算效率。
- 低成本硬件配置:X-R1专注于用常见的硬件配置(如4块3090或4090 GPU)进行训练,降低硬件成本。
- 日志监控:集成Wandb等工具,提供训练过程的可视化监控,帮助用户实时了解训练状态。
如何运行 X-R1
1. 安装依赖
确保你的环境中安装了 CUDA >= 12.4,并创建一个新的 Conda 环境:
conda create -n xr1 python=3.11
conda activate xr1
pip install -r requirements.txt
pip install flash-attn
2. 创建输出目录
mkdir output
3. 配置与训练
3.1 0.5B 模型
对于 0.5B 模型,假设你有 4 块 NVIDIA 3090 GPU。你可以使用以下命令启动训练:
ACCELERATE_LOG_LEVEL=info \\
accelerate launch \\
--config_file recipes/zero3.yaml \\
--num_processes=3 \\
src/x_r1/grpo.py \\
--config recipes/X_R1_zero_0dot5B_config_peft.yaml \\
> ./output/x_r1_0dot5B_sampling.log 2>&1
--num_processes=3:表示使用 3 个进程进行训练,其中 1 个 GPU 用于在线推理引擎(vLLM),以加快 GRPO 采样。--config recipes/X_R1_zero_0dot5B_config_peft.yaml:指定配置文件,用于 0.5B 模型的训练。
3.2 1.5B 模型
对于 1.5B 模型,配置类似,但需要调整一些参数。假设你有 4 块 NVIDIA 3090 GPU,可以使用以下命令启动训练:
ACCELERATE_LOG_LEVEL=info \\
accelerate launch \\
--config_file recipes/zero3.yaml \\
--num_processes=3 \\
src/x_r1/grpo.py \\
--config recipes/X_R1_zero_1dot5B_config.yaml \\
> ./output/x_r1_1dot5B_sampling.log 2>&1
3.3 3B 模型
对于 3B 模型,训练时间会更长,大约需要 16 小时。你可以使用以下命令启动训练:
ACCELERATE_LOG_LEVEL=info \\
accelerate launch \\
--config_file recipes/zero3.yaml \\
--num_processes=3 \\
src/x_r1/grpo.py \\
--config recipes/X_R1_zero_3B_config.yaml \\
> ./output/x_r1_3B_sampling.log 2>&1
4. 示例:中文数学推理
X-R1 支持中文数学问题的推理,可以通过以下命令启动训练:
ACCELERATE_LOG_LEVEL=info \\
accelerate launch \\
--config_file recipes/zero3.yaml \\
--num_processes=3 \\
src/x_r1/grpo.py \\
--config recipes/examples/mathcn_zero_3B_config.yaml \\
> ./output/mathcn_3B_sampling.log 2>&1
该配置文件专门用于中文数学问题的训练,使用 4 块 NVIDIA 3090 GPU,大约需要 16 小时完成 3B 模型的训练。
5. 训练结果与日志
5.1 训练日志
- 0.5B 模型日志 – Google Drive:https://drive.google.com/file/d/1m-w0B2L9o-bwGDgaOtWFLR0C0MAEBTFQ/view?usp=sharing
- 1.5B 模型日志 – Google Drive:https://drive.google.com/file/d/11tBShY206Pu_SxWE0M-mG2_Cdf9mFNig/view?usp=sharing
- 3B 模型日志 – Google Drive:https://drive.google.com/file/d/1t4WzsK0aMrULYKjKsKH29LsWQMeTDjTb/view?usp=sharing
5.2 训练曲线
训练过程中,模型的表现可以通过奖励曲线来观察。以下是 3B 模型在中文数学推理任务中的奖励曲线:
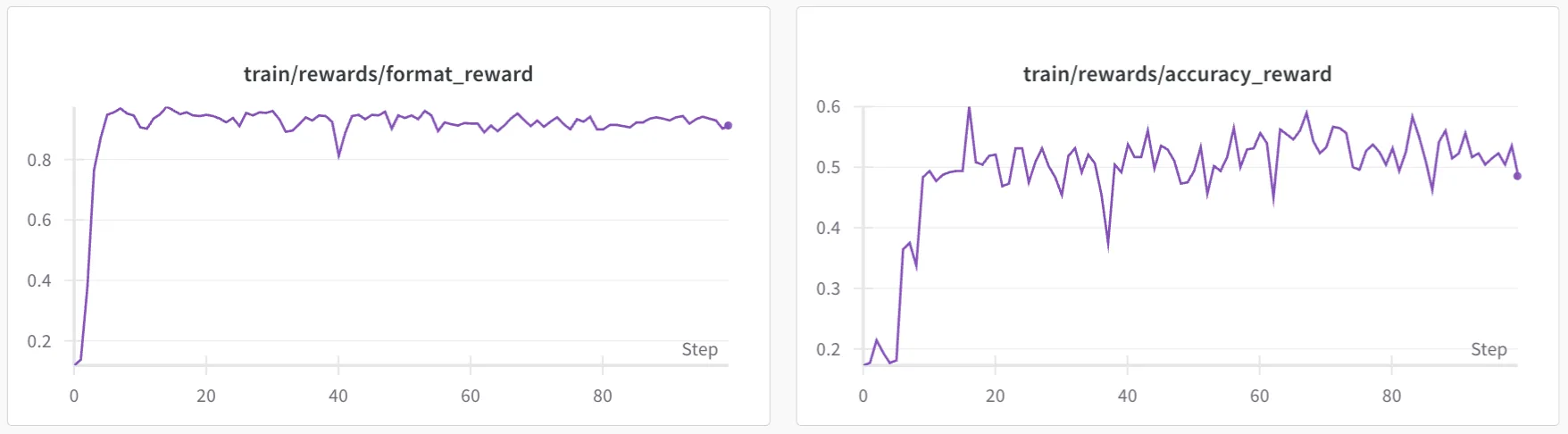
5.3 中文数学推理的“顿悟时刻”
在训练过程中,模型会逐渐学会解决复杂的数学问题,并出现“顿悟时刻”。以下是一些示例:
- 示例1

- 示例2

资源
- GitHub 仓库:https://github.com/dhcode-cpp/X-R1
- HuggingFace 仓库:https://huggingface.co/xiaodongguaAIGC
